TL;DR
Hardware got wider, not faster. More cores, more bandwidth, huge vector units — but clocks, IPC, and latency flatlined. Old rules like “memory is faster than disk” are breaking. To go fast today, you have to play the new game.
“CPUs keep getting faster every generation”
Over the past 20 years or so computer hardware has evolved such that some facts we “know” about computers are wrong. Even among computer scientists, or perhaps especially among computer scientists, intuitions are off target.
Let's consider a simple statement: “CPUs keep getting faster every generation”
This is obviously not wrong entirely. Computers are certainly getting faster and more capable. When we put some hard numbers to this we can see a lot of things have been and continue to be improving exponentially.
What is scaling?
If we look at the promotional materials for CPUs, you can see the product specs are clearly improving. For example:
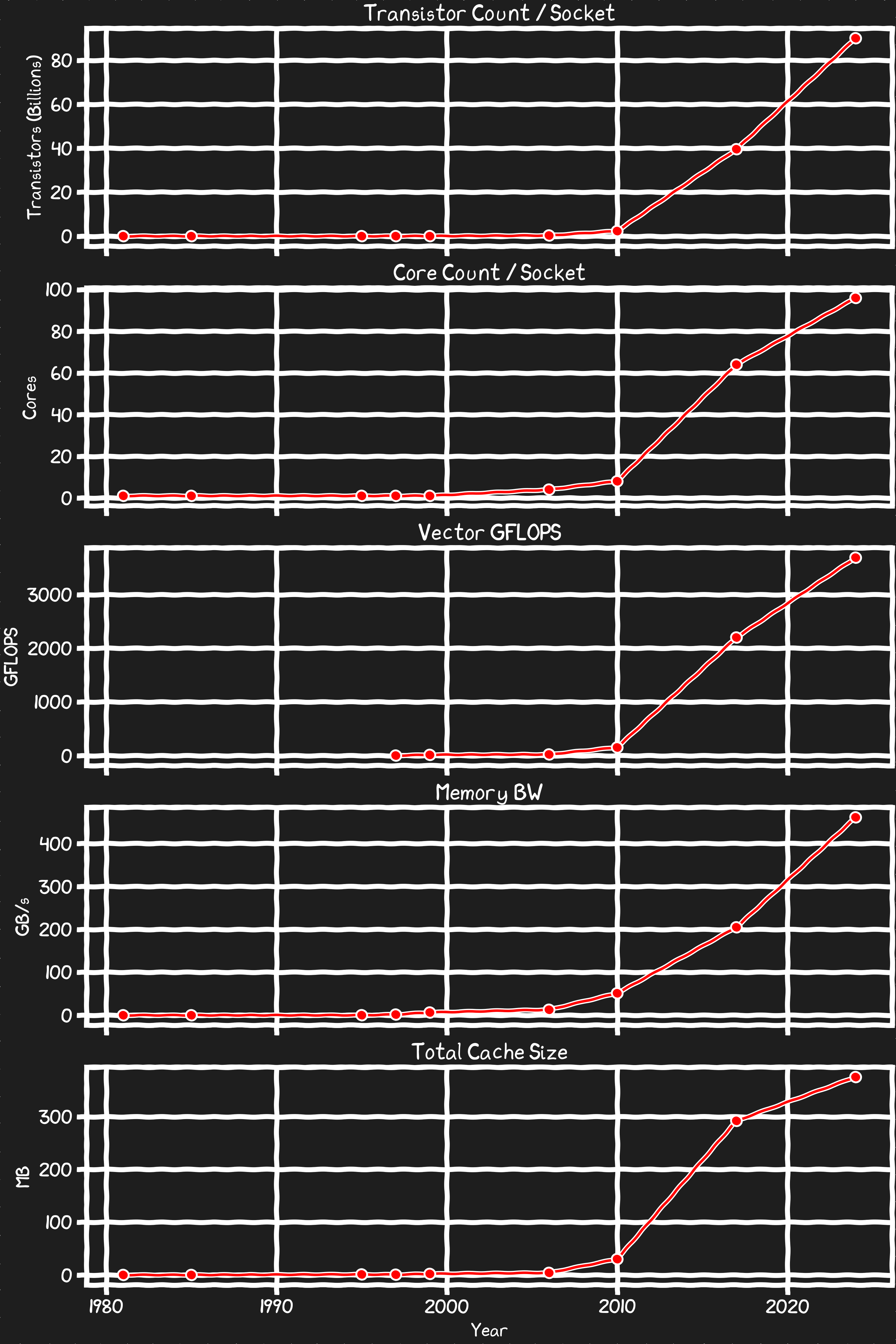
Transistor Count
As much as there is hand wringing about the death of Moores Law, we are producing CPUs with ever increasing transistor counts. Is this driven by more silicon being packaged in increasing sophisticated ways and moving into the Z axis rather than the core feature size shrinking of the past? Are we doubling slower than in the past? Who cares?
Core Counts
The logic transistors that dominate the size of a core on a chip scale well with the lithography changes. This makes scaling CPU core counts cut and paste easy.
Vector Operations
For vectorized operations underlying graphics, physics and AI calculations processors have been innovating at a rapid rate. Although compilers don’t always find potential optimizations, the industry has done a good job of having support for new vector instructions in compilers and intrinsics in sync with release of the hardware. The performance gains for implementing the latest vector calcs can be dramatic.
Memory Bandwidth
The industry has been very good at cooperatively developing and adopting new standards that have enabled steady increases in memory bandwidth. Without sufficient memory bandwidth processor can easily get stalled.
Caches
As fast as memory is improving it is nowhere near fast enough to support the instantaneous demands for data and instructions to feed the explosion of cores and vector operations that we’ve seen. Caches are and have been critical to keeping processors productive. Although the L1 and L2 die caches have not grown very rapidly the L3+ caches have been steadily increasing.
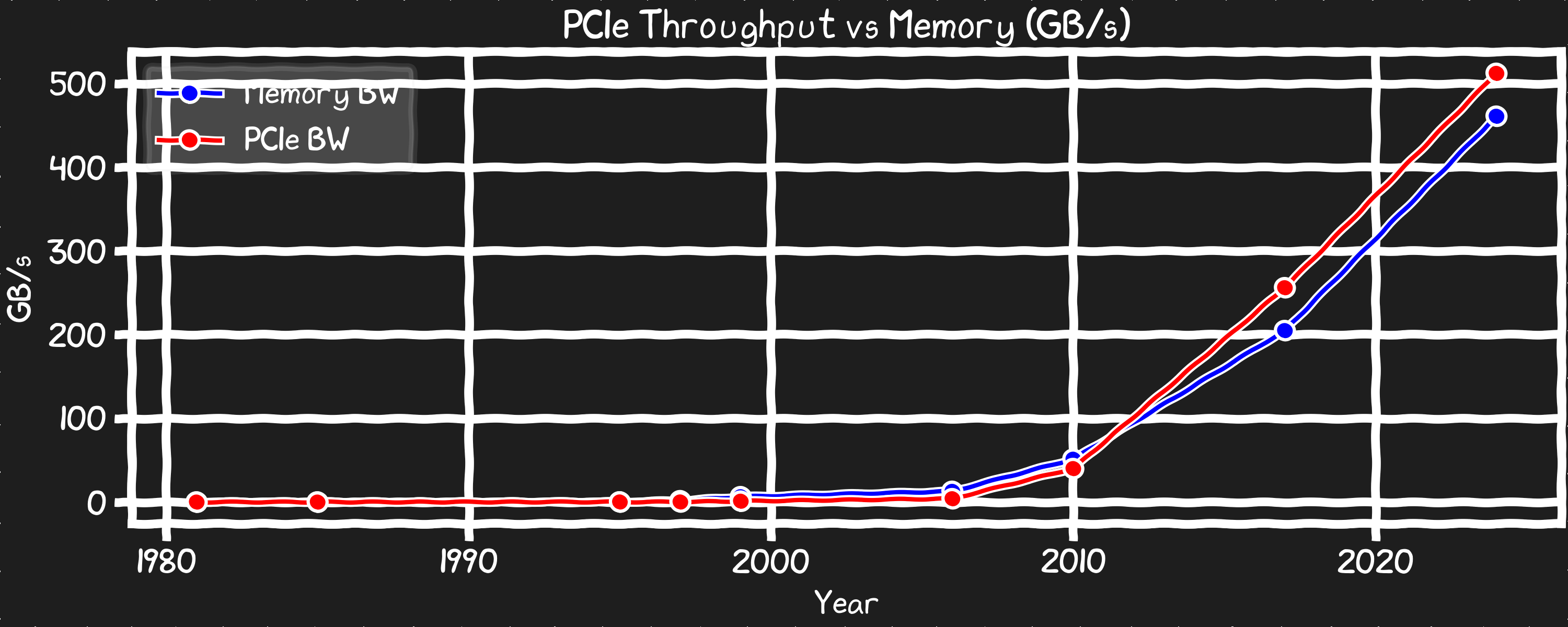
PCIe Bandwidth
The ability to get data in and out of the CPU has been consistently doubling every generation which has enabled NVMe and networking to keep pace. On paper the aggregate PCIe bandwidth is higher than the RAM bandwidth for modern server CPUs.
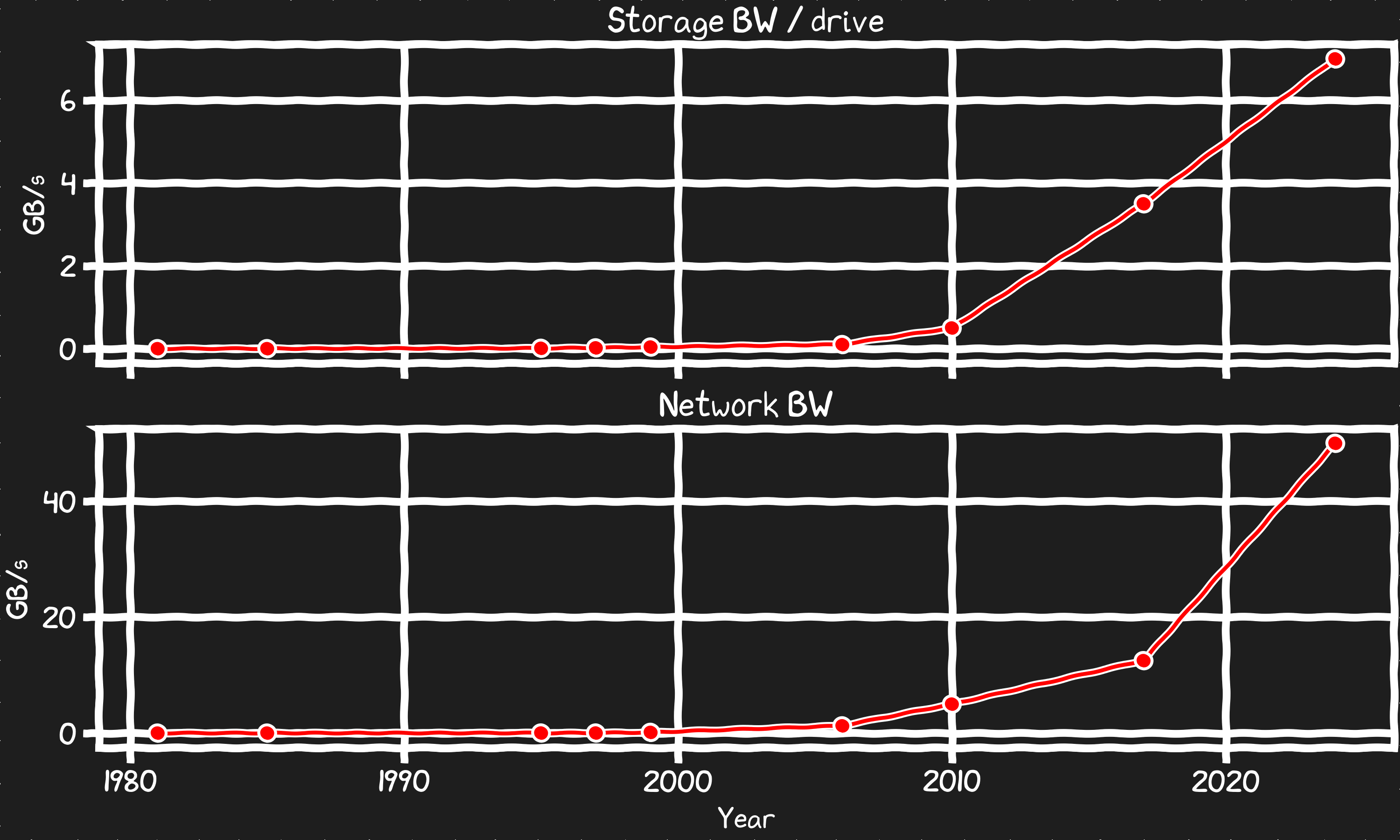
Storage and Network Bandwidth
NVMe SSD have made disks incredibly fast as they are designed with peak PCIe throughput in mind. Network interface cards and the protocols they use have also kept pace in some respects drafting off the same serial communication improvements that enable the PCIe bus connections they use to communicate to the rest of the system with.
What is NOT scaling?
With all these metrics going up like a Bored Ape NFT in 2021 what fault could I possibly find with the statement “computer hardware keeps getting faster every generation”? What we’ve shown so far is that if you are building a supercomputer doing parallel computing with perfectly optimized vector math then CPUs are getting much faster. Which is funny because that describes AI and HPC workloads which are mostly done in GPUs, not CPUs. GPUs lean entirely into the scaling metrics which is why they are so fast at these workloads. What about “traditional” or “normal” programs, you know, single threaded not particularly vector friendly programs? Well it’s not as cheery a story.
If we look at the fundamentals that drove the early computer revolution, when the field of computer science was born we see they have been stagnant for decades.
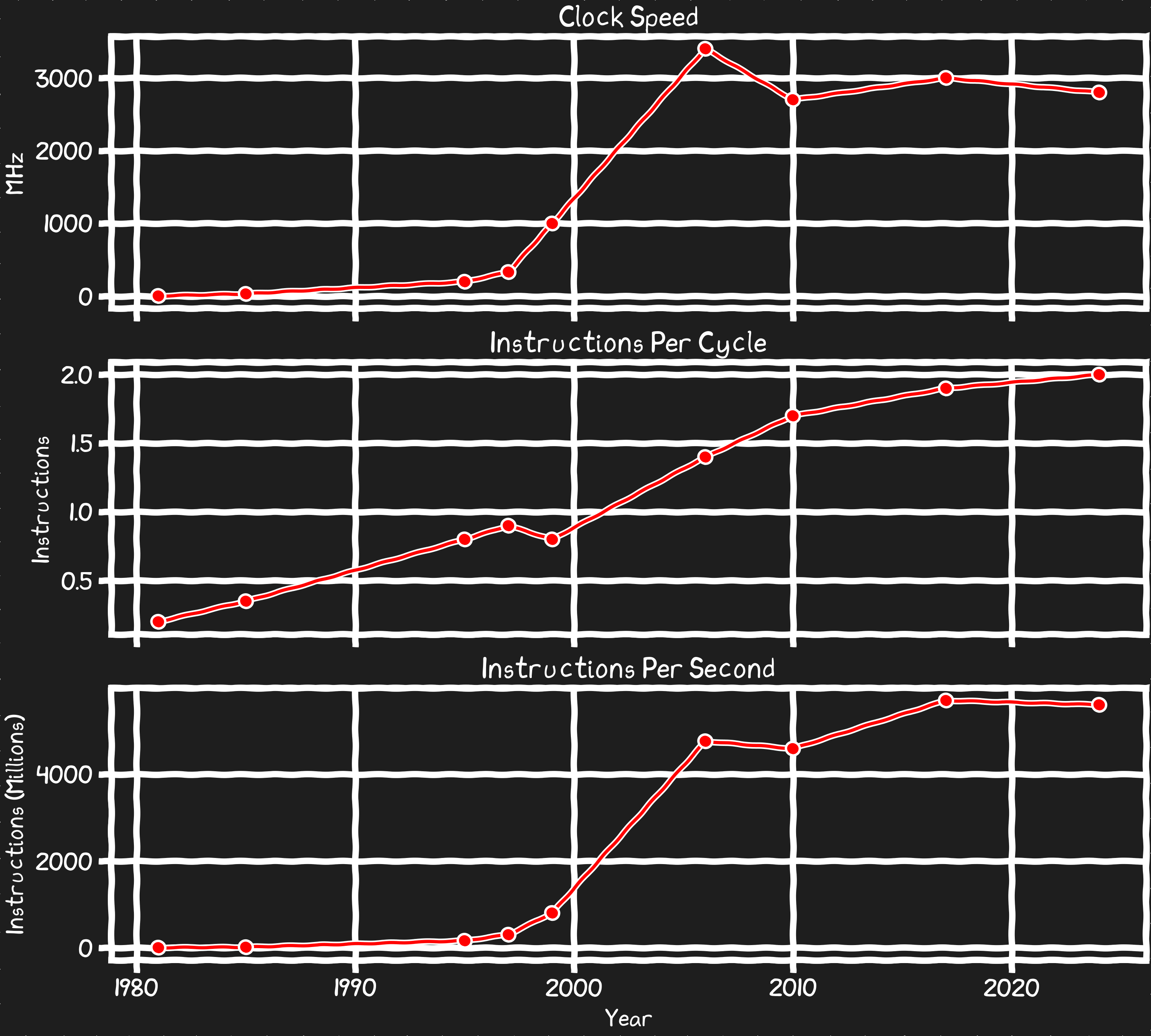
Instructions Per Second
Clock Speed
For the first 25yrs of the x86 computers got much faster clocks every generation. That was the basis of a lot of competitive advantage and it made your computer faster in every sense. Then it stopped. Practical clock speeds have been largely stagnant for 20 years now.
Instruction Per Clock
Early x86 processors took a few clocks to execute most instructions, modern processors have been able parallelize to where they can actually execute 2 instructions every clock. However this is a slowly improving metric that doesn’t offset the lack of scaling in clockspeed. If you aren’t using vector units, the work a given CPU core can do has changed modestly for the past 20 years.
Instructions Per Second
If we take the clock speed and IPC into consideration we can look at the compute a core can do with non-vector instructions. I think the resulting Instructions Per Second metric shows more cleanly that the compute capability of a given core has stagnated.
Latency
Memory Latency
The core mechanism for how DRAM works has remained pretty constant as the interface and protocol has evolved. As clock speed advanced rapidly the latency to memory shrank until we hit the fundamental limits involving things like how fast we can charge and discharge the lines in a DRAM chip. The time it takes to access the first byte of data in a cache miss has been the same for 30yrs.

The problem is that when there are flatlined metrics that have impact on ones that are growing the relative impact grows. Because of this the cost of some operations is a lot higher than what intuition suggests.
For example, let’s reframe the DRAM cache miss latency in terms of its cost in instructions we don’t run while we wait on memory.
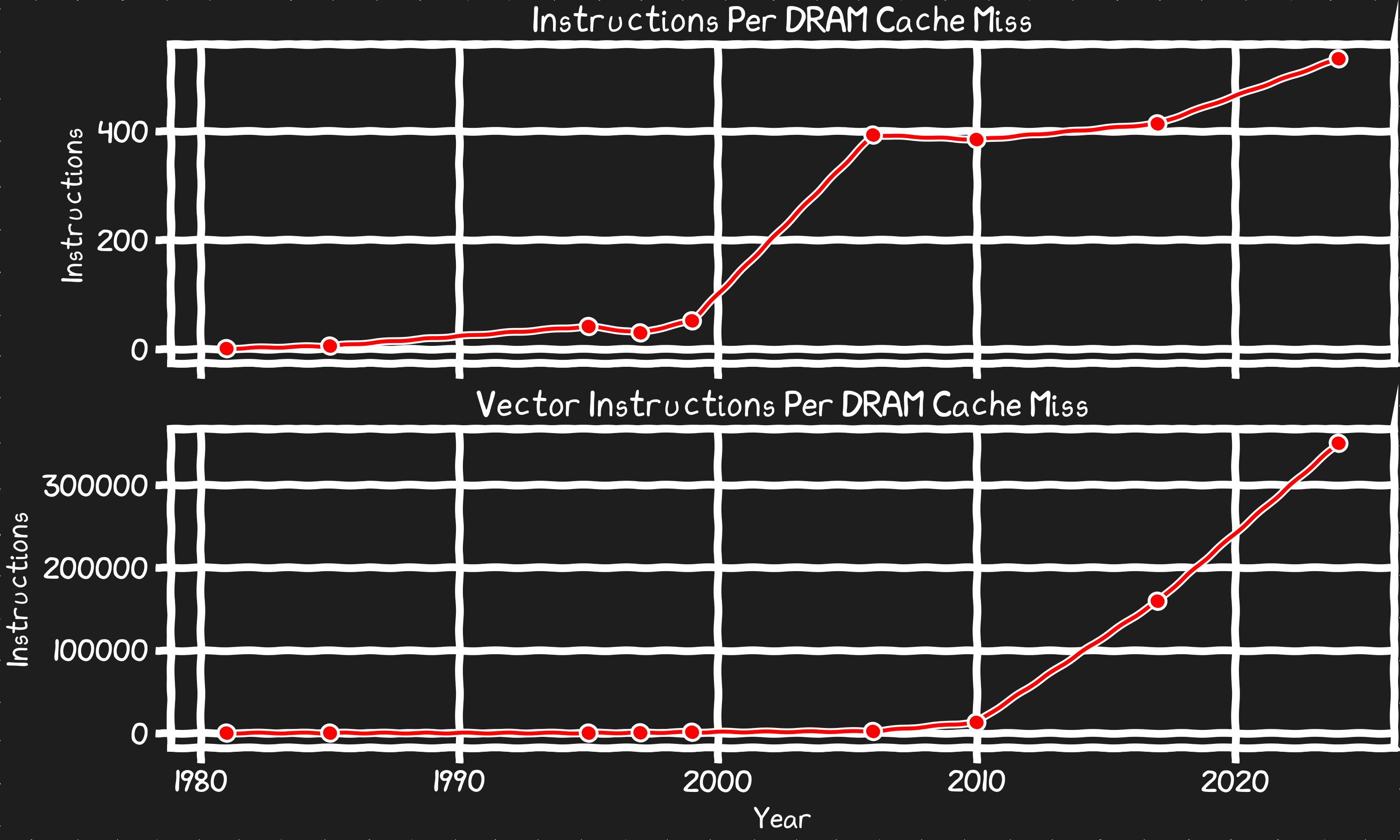
20 years ago when the instructions per second per core peaked the real cost of a cache miss exploded. In the 90s a cache miss would cost only dozens of instructions but now it’s 500+. If you consider the impact in terms of vector operations you could run, it’s up to 350,000 operations that are done while you wait for the first byte from memory on a miss.
Disk Latency SSDs brought a 100x reduction in latency. However, SSD latency has stagnated for similar reasons as DRAM. We could see products that are a bit worse and a bit better as products differentiate into ultra dense QLC/PLC and SLC high performance product lines. But these will stay in an order of magnitude of where these products have been for the last decade. While there is still a lot of benefit left for optimizing systems to take advantage of the huge improvement in latency SSDs can provide, this metric isn’t going anywhere until we get a NAND replacement that does better than Optane did.
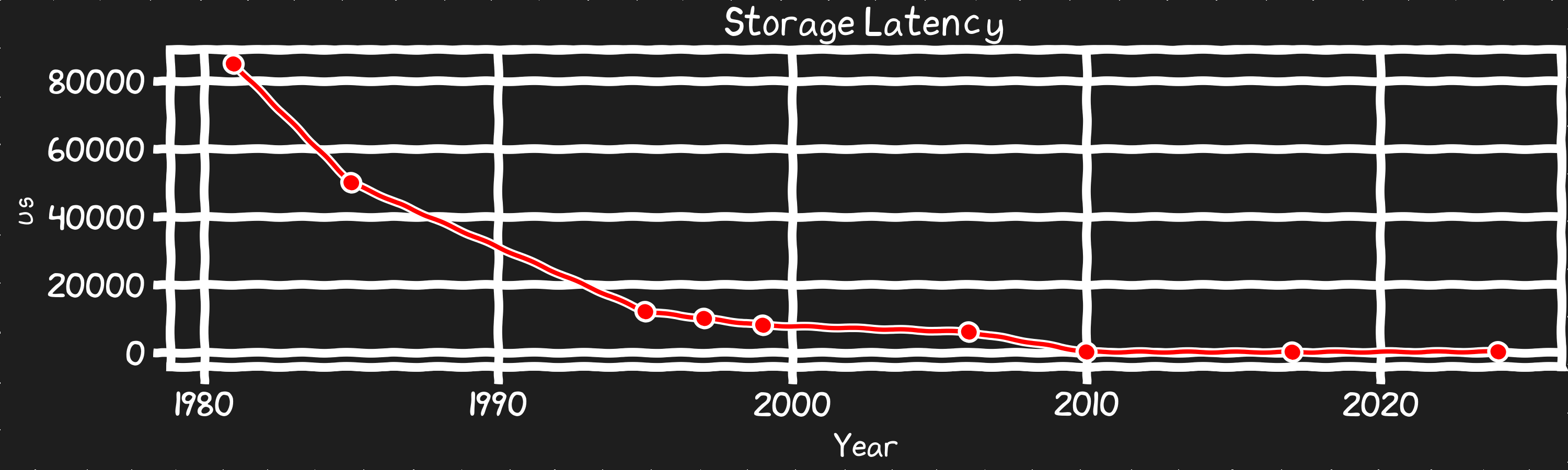
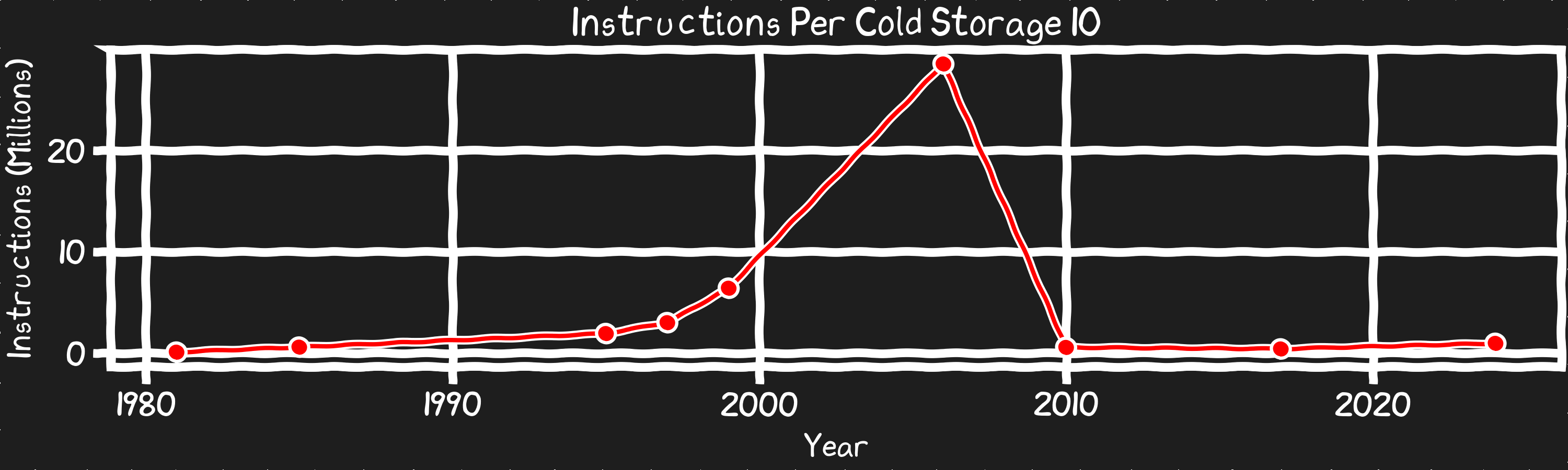
Reframing the cost of a storage IO in terms of instructions, tells a different story. Disk access latency, even with SSDs is high, however there has been a huge change. Until SSDs went mainstream the real impact of a program waiting on a disk IO was huge and growing and the bandwidth was stalled. SSD’s dropped the latency by 50x and held it steady, while the bandwidth of these disks is exponentially growing. The result of these trends is that the habits and the years of effort to mitigate the impact of disk access now hurts rather than helps system performance.
What does the future hold?
Good News
The industry is still making progress. We are getting more cores, bandwidth, and vector ops. AI is all about bandwidth and parallel compute, so it’s able to take full advantage of new hardware. And there don't seem to be any major technical roadblocks on the horizon to prevent continued growth for the things that are now scaling. Not that it will be easy, but there are paths forward to improve density, bandwidth, and parallelize.
Bad News
For the things that aren't scaling? There isn't much hope this changes for now. A concerning number of these are because we’re starting to hit limits the laws of physics impose on the core technologies we’ve been refining and shrinking for 75 years now. The quantum behavior of the few electrons that can exist in structures best measured in angstroms is very different from the easy to model classical behavior we counted on 25 years ago. Latency and clock speeds are both limited by the laws of physics, or at least with the materials and techniques we have today progress would come at too high a cost.
The problem with traditional software
Where does that leave non-AI code? I'll call this code traditional programming, which includes the apps that AI is feverishly generating, pretty much everything written in TypeScript, even much of system software and operating systems code. This kind of a computing by it's nature doesn't take advantage of the new hardware. It's often single threaded, not really written for vectorization, and includes a lot branches that can lead to cache misses. We used to count on this kind of code getting faster as the hardware got faster. Now new hardware can't be counted on to scale performance. Things like clock speed improvements that drove performance gains in the past have stagnated. There are modest improvements (probably 5%-10% per generation) to be had as cache sizes increase and CPUs tweak the architecture. However, unless we start to rethink the way we write software, most traditional software will be stuck in the past, missing out on the exponential improvements.
What does this means for me?
These stagnate metrics underpin much of computer science dogma, the rules of thumb and best practices. Compounded drift between stagnate and exponential performance factors leads us to the now where the dogma is wrong. Not just outdated some are exactly wrong. Even the theoretical frameworks of computer science need to be revisited, because much like newtonian physics doesn't account for quantum effects, they can lead to wrong conclusions if you don't consider the orders of magnitude of difference in cost for various operations.
For example, everyone knows accessing things in memory is faster than getting it from disk. But thats not always true anymore given the factors I explained above.
Coming up in the next episode!
If you like being stuck with 90s level performance and paying for billionaires 2nd weddings then ignore this series. If not then follow as I explore how you can improve performance by leaning into exponential growth and avoid stagnate performance.
- Sourcing data from disk can be faster than from memory? What!!??
- O(√n) can be faster than O(log n)? Is Big O notation a conspiracy by big computer science to keep us down?
- Will everything just be AI? The answer is terrifying, titillating, and almost too much to bear!
Stay tuned for shocking conclusion!
Jared Hulbert
NOTE:
Data used for the charts was researched and compiled by ChatGPT, I spot checked it and found it was accurate enough for the narrative. raw data